Introduction data enrichment based on email addresses and domain names
03.08.2020 - Jay M. Patel - Reading time ~4 Minutes
Data enrichment is a general term to denote any processes which enhance and enrich your existing database with additional information that can be used to drive your business goals such as marketing, sales and lead generation, customer relations by targeted outreach, and preventing customer churn.
Plainly speaking, all you are doing is going out to a third-party data vendor and fetching additional data based on some common key. One of the most keys for data enrichment is searching based on an email address or company’s domain address.
Just giving an email address as an input can be enough to get back information such as a person’s name, age, gender, social media handles such Twitter, Linkedin, short bio, phone numbers, work address, time zone, job title, seniority etc.
You can also get company-specific information related to a person’s employment such as the size of company, location, size, stock ticker, postal addresses, etc.
In this post, we will show you data enrichment in action by using freely available public APIs. We will start from scratch and get a list of email addresses and names of employees associated with a particular domain address using the Email address database API. Once we have that, we will fetch data from another API which returns results from a person search engine that gets us enriched information such as Linkedin handles, short bio ,etc.
You will have to register at Algorithmia to get the free API keys (no credit card etc. required). You will get about free 10,000 credits when you sign up which should be plenty to call it hundreds of times.
Let’s start things off by requesting email addresses associated with the domain address (“wsj.com”) of the Wall Street Journal.
import Algorithmia
input = {
"domains": "wsj.com",
"page": "1"
}
client = Algorithmia.client('YOUR_AlGORITHMIA_KEY')
algo = client.algo('specrom/Get_email_addresses_by_domain/0.2.3')
response_dict = algo.pipe(input).result
print(response_dict["Emails"])[{'also_extracted_on': 179,
'email_address': 'moderator@wsj.com',
'first_name': '',
'last_name': '',
'last_seen_on': '2020-08-01',
'url': 'https://www.wsj.com/articles/north-korea-reports-its-first-apparent-covid-19-case-11595722635'},
{'also_extracted_on': 165,
'email_address': 'petra.sorge@wsj.com',
'first_name': 'petra',
'last_name': 'sorge',
'last_seen_on': '2020-08-01',
'url': 'https://www.finanznachrichten.de/nachrichten-2020-07/50251284-umwelthilfe-onlinehandel-an-illegaler-geraete-entsorgung-mitschuldig-015.htm'},
{'also_extracted_on': 130,
'email_address': 'andreas.kissler@wsj.com',
'first_name': 'andreas',
'last_name': 'kissler',
'last_seen_on': '2020-08-01',
'url': 'https://www.finanznachrichten.de/nachrichten-2020-07/50246132-dreyer-haelt-verlaengerung-der-mehrwertsteuersenkung-fuer-moeglich-015.htm'},
{'also_extracted_on': 70,
'email_address': 'wsj.ltrs@wsj.com',
'first_name': 'wsj',
'last_name': 'ltrs',
'last_seen_on': '2020-07-24',
'url': 'http://www.blacks4barack.net/2010/06/watch-presidents-weekly-address.html'},
{'also_extracted_on': 63,
'email_address': 'dave.sebastian@wsj.com',
'first_name': 'dave',
'last_name': 'sebastian',
'last_seen_on': '2020-08-01',
'url': 'https://www.marketwatch.com/story/po-cruises-extends-sailing-pause-in-australia-2020-07-23'},
{'also_extracted_on': 40,
'email_address': 'matt.grossman@wsj.com',
'first_name': 'matt',
'last_name': 'grossman',
'last_seen_on': '2020-08-01',
'url': 'https://www.marketscreener.com/DOW-INC-56112378/news/Dow-Records-2Q-Loss-as-Sales-Fall-Across-Categories-30976109/?utm_medium=RSS&utm_content=20200723'},
.
.
.
Let us extract just the first names, last names email addresses and domain address from the above JSON so that we can directly use it as an input to the people search API.
return_list = []
for res in response_dict["Emails"]:
if res["first_name"] != '':
temp_dict = {}
temp_dict["emails"] = res["email_address"]
temp_dict["first_name"] = res["first_name"]
temp_dict["last_name"] = res["last_name"]
temp_dict["domain"] = res["email_address"].split('@')[1]
return_list.append(temp_dict)
return_list[{'domain': 'wsj.com',
'emails': 'petra.sorge@wsj.com',
'first_name': 'petra',
'last_name': 'sorge'},
{'domain': 'wsj.com',
'emails': 'andreas.kissler@wsj.com',
'first_name': 'andreas',
'last_name': 'kissler'},
{'domain': 'wsj.com',
'emails': 'wsj.ltrs@wsj.com',
'first_name': 'wsj',
'last_name': 'ltrs'},
{'domain': 'wsj.com',
'emails': 'dave.sebastian@wsj.com',
.
.
{'domain': 'wsj.com',
'emails': 'andrea.thomas@wsj.com',
'first_name': 'andrea',
'last_name': 'thomas'}]
People search API returns five results for a given input; we can enrich our database by specifically extracting linkedin titles, urls etc. Since we are working with email addresses associated with Wall Street Journal, it is also relevant to extract urls from Muckrack which is a journalist database and contains recent news articles by a particular journalist.
for val in return_list[:5]:
input = val
client = Algorithmia.client('simp/UVi9WzPfbAVafQRi7+aNa61')
algo = client.algo('specrom/People_search/0.3.3')
response = algo.pipe(input).result
#print(response["Results"])
val["linkedin_url"] = ''
val["linkedin_title"] = ''
val["linkedin_snippet"] = ''
val["muckrack_url"] = ''
val["muckrack_title"] = ''
val["muckrack_snippet"] = ''
val["bio_url"] = ''
val["bio_title"] = ''
val["bio_snippet"] = ''
for result in response["Results"]:
if 'linkedin' in result["url"]:
val["linkedin_url"] = result["url"]
val["linkedin_title"] = result["title"]
val["linkedin_snippet"] = result["snippet"]
if 'muckrack' in result["url"]:
val["muckrack_url"] = result["url"]
val["muckrack_title"] = result["title"]
val["muckrack_snippet"] = result["snippet"]
if val["first_name"] in result["title"].lower() or val["last_name"] in result["title"].lower() and 'muckrack' not in result["url"]:
val["bio_url"] = result["url"]
val["bio_title"] = result["title"]
val["bio_snippet"] = result["snippet"]As a final step, let’s load this up on a dataframe.
import pandas as pd
import numpy as np
df = pd.DataFrame(return_list[:5])
df.head()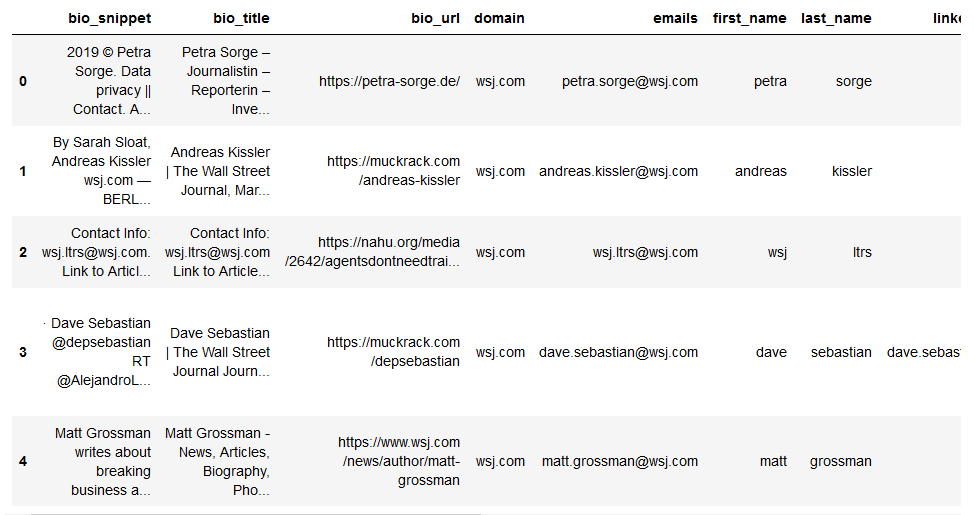
This is just an example of how quickly you can enrich your database and power your sales and marketing strategies.