Using Twitter rest APIs in Python to search and download tweets in bulk
01.02.2019 - Jay M. Patel - Reading time ~5 Minutes
Getting Twitter data
Let’s use the Tweepy package in python instead of handling the Twitter API directly. The two things we will do with the package are, authorize ourselves to use the API and then use the cursor to access the twitter search APIs.
Let’s go ahead and get our imports loaded.
import tweepy
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set()
%matplotlib inlineTwitter authorization
To use the Twitter API, you must first register to get an API key. To get Tweepy just install it via pip install Tweepy. The Tweepy documentation is best at explaining how to authenticate, but I’ll go over the basic steps.
Once you register your app you will receive API keys, next use Tweepy to get an OAuthHandler. I have the keys stored in a separate config dict.
config = {"twitterConsumerKey":"XXXX", "twitterConsumerSecretKey" :"XXXX"}
auth = tweepy.OAuthHandler(config["twitterConsumerKey"], config["twitterConsumerSecretKey"])
redirect_url = auth.get_authorization_url()
redirect_urlNow that we’ve given Tweepy our keys to generate an OAuthHandler, we will now use the handler to get a redirect URL. Go to the URL from the output in a browser where you can allow your app to authorize your account so you can get access to the API.
Once you’ve authorized your account with the app, you’ll be given a PIN number. Use that number in Tweepy to let it know that you’ve authorized it with the API.
pin = "XXXX"
auth.get_access_token(pin)Searching for tweets
After getting the authorization, we can use it to search for all the tweets containing the term “British Airways”; we have restricted the maximum results to 1000.
query = 'British Airways'
max_tweets = 10
searched_tweets = [status for status in tweepy.Cursor(api.search, q=query,tweet_mode='extended').items(max_tweets)]
search_dict = {"text": [], "author": [], "created_date": []}
for item in searched_tweets:
if not item.retweet or "RT" not in item.full_text:
search_dict["text"].append(item.full_text)
search_dict["author"].append(item.author.name)
search_dict["created_date"].append(item.created_at)
df = pd.DataFrame.from_dict(search_dict)
df.head()Out:
text author created_date
0 @RwandAnFlyer @KenyanAviation @KenyaAirways @U... Bkoskey 2019-03-06 10:06:14
1 @PaulCol56316861 Hi Paul, I'm sorry we can't c... British Airways 2019-03-06 10:06:09
2 @AmericanAir @British_Airways do you agree wit... Hat 2019-03-06 10:05:38
3 @Hi_Im_AlexJ Hi Alex, I'm glad you've managed ... British Airways 2019-03-06 10:02:58
4 @ZRHworker @British_Airways @Schmidy_87 @zrh_a... Stefan Paetow 2019-03-06 10:02:33Language detection
The tweets downloaded by the code above can be in any language, and before we use this data for further text mining, we should classify it by performing language detection.
In general, language detection is performed by a pretrained text classifier based on either the Naive Bayes algorithm or more modern neural networks. Google’s compact language detector library is an excellent choice for production-level workloads where you have to analyze hundreds of thousands of documents in less than a few minutes. However, it’s a bit tricky to set up and as a result, a lot of people rely on calling a language detection API from third-party providers like Algorithmia which are free to use for hundreds of calls a month (sign up required).
Let’s keep things simple in this example and just use a Python library called Langid which is orders of magnitude slower than the options discussed above but should be OK for us in this example since we are only to analyze about a hundred tweets.
from langid.langid import LanguageIdentifier, model
def get_lang(document):
identifier = LanguageIdentifier.from_modelstring(model, norm_probs=True)
prob_tuple = identifier.classify(document)
return prob_tuple[0]
df["language"] = df["text"].apply(get_lang)We find that there are tweets in four unique languages present in the output, and only 45 out of 100 tweets are in English, which are filtered as shown below.
df["language"].unique()
Out:
array(['en', 'rw', 'nl', 'es'], dtype=object)df_filtered = df[df["language"]=="en"]
df_filtered.shape
Out:
(45, 4)Getting sentiments score for tweets
We can take df_filtered created in the preceding section and run it through a pretrained sentiments analysis library. For illustration purposes we are using the one present in Textblob library, however, I would highly recommend using a more accurate sentiments model such as those in coreNLP or train your own model using Sklearn or Keras.
Alternately, if you choose to go via the API route, then there is a pretty good sentiments API at Algorithmia.
from textblob import TextBlob
def get_sentiments(text):
blob = TextBlob(text)
# sent_dict = {}
# sent_dict["polarity"] = blob.sentiment.polarity
# sent_dict["subjectivity"] = blob.sentiment.subjectivity
if blob.sentiment.polarity > 0.1:
return 'positive'
elif blob.sentiment.polarity < -0.1:
return 'negative'
else:
return 'neutral'
def get_sentiments_score(text):
blob = TextBlob(text)
return blob.sentiment.polarity
df_filtered["sentiments"]=df_filtered["text"].apply(get_sentiments)
df_filtered["sentiments_score"]=df_filtered["text"].apply(get_sentiments_score)
df_filtered.head()
Out:
text author created_date language sentiments sentiments_score
0 @British_Airways Having some trouble with our ... Rosie Smith 2019-03-06 10:24:57 en neutral 0.025
1 @djban001 This doesn't sound good, Daniel. Hav... British Airways 2019-03-06 10:24:45 en positive 0.550
2 First #British Airways Flight to #Pakistan Wil... Developing Pakistan 2019-03-06 10:24:43 en positive 0.150
3 I don’t know why he’s not happy. I thought he ... Joyce Stevenson 2019-03-06 10:24:18 en negative -0.200
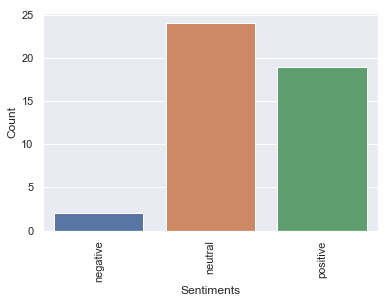
4 Fancy winning a global holiday for you and a f... Selective Travel Mgt 🌍 2019-03-06 10:23:40 en positive 0.360Let us plot the sentiments score to see how many negative, neutral, and positive tweets people are sending for “British airways”. You can also save it as a CSV file for further processing at a later time.
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
%matplotlib inline
g = sns.countplot(df_filtered["sentiments"])
loc, labels = plt.xticks()
g.set_xticklabels(labels, rotation=90)
g.set_ylabel("Count")
g.set_xlabel("Sentiment %")