How to create pdf documents in python using FPDF library
01.08.2020 - Jay M. Patel - Reading time ~3 Minutes
PDF files are ubiquitous in our daily life and it’s a good idea to spend few minutes to learn how to programmatically generate it in Python.
In this tutorial, we will take structured data in JSON and convert that into a pdf. Ideally, pdfs contain text paragraphs, hyperlinks and images, so we will work with a dataset containing all of that for better real world experience.
Firstly, let us fetch the data from a publicly available API containing scraped news articles from past 24 hours. You will have to register at Algorithmia to get the free API keys (no credit card etc. required). You will get about free 10,000 credits when you sign up which should be plenty to call it hundreds of times.

Figure 1: API example showing input/output schema
import Algorithmia
clean_response_list = []
for i in range(1,3):
print("fetching page ", str(i))
input = {
"domains": "",
"topic": "politics",
"q": "",
"qInTitle": "",
"content": "true",
"author_only": "true",
"page": str(i)
}
client = Algorithmia.client(YOUR_ALGO_KEY)
algo = client.algo('specrom/LatestNewsAPI/0.1.6')
response_dict = algo.pipe(input).result
print("Total results found: ", response_dict["totalResults"])
clean_response_list = clean_response_list + response_dict["Article"]
len(clean_response_list)Output
Total results found: 2617
fetching page 2
Total results found: 2617
Now, let us load this data into a dataframe and view the top results.
import pandas as pd
import numpy as np
df = pd.DataFrame(clean_response_list)
df.head()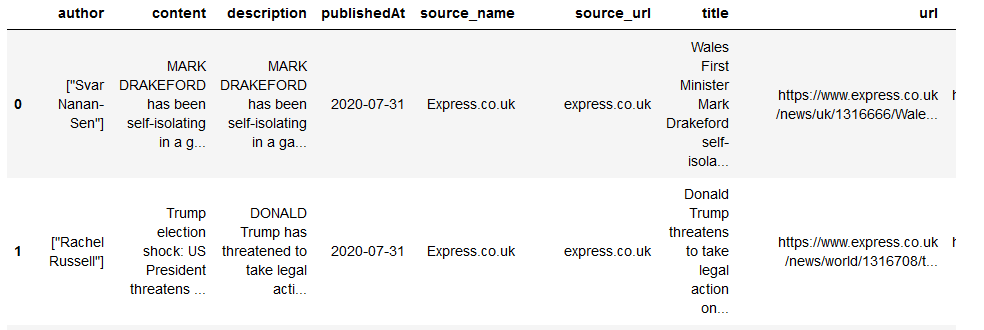
Figure 2: Pandas Dataframe with scraped news data
Alright, as you can see, we have quite a few types of data in the above dataset. Now, let us use the title, url, and images, and content to create a pdf.
We will be using Python port of a popular PHP based PDF library called FPDF. Install it using pip install fpdf. Let us initialize an empty FPDF object and set font to Times new roman with font size of 12.
from fpdf import FPDF
pdf = FPDF()
pdf.alias_nb_pages()
pdf.add_page()
pdf.set_font('Times', '', 12)
pdf.cell(0,10, txt = '',ln=1 )Now, we can iterate through the dataframe rows aand add article url, title and full text to our PDF object.
If you want to create a multiline block of text, you should use multicell as shown below. By default, Python 3 encodes the strings as utf-8 however, FPDF package expects it in latin-1 so you will have to manually change encoding as shown.
pdf.multi_cell(0, 10,txt="demo_string".encode().decode('latin-1', 'strict'))Similarly, you can create a single line text by using the cell.
pdf.cell(0,10,txt="demo string".encode().decode('latin-1', 'strict'),ln=1)We can close the pdf object and save it as a file as shown.
pdf.output('news_articles.pdf', 'F')We will bring all of these elements together and as an additional challenge, we will also download cover image from each article and delete it after we are done.
import requests
import os
df_filtered = df.iloc[:25]
image_list = []
count = 1
for i in range(len(df_filtered)):
#for i in range(5):
if True: # specify some other filtering criteria here if you want
try:
pdf.cell(0,10, txt = str(count),ln=1 )
count = count+1
pdf.cell(0, 10,txt='Article url', link = df_filtered.url.iloc[i].encode().decode('latin-1', 'strict'),ln=1)
pdf.multi_cell(0, 10,txt=df_filtered.title.iloc[i].encode().decode('latin-1', 'strict'))
pdf.cell(0,10, txt = '\n',ln=1 )
try:
sample_ss = df_filtered.urlToImage.iloc[i]
image_name = 'image_name' + str(i) + '.jpg'
if sample_ss.split(".")[-1] == 'jpg':
img_data = requests.get(sample_ss).content
with open(image_name, 'wb') as handler:
handler.write(img_data)
pdf.image(image_name, w = 100, h = 50)
image_list.append(image_name)
except Exception as E:
print(str(E))
pass
pdf.cell(0,10, txt = '\n',ln=1 )
pdf.multi_cell(0,10,txt=df_filtered.content.iloc[i].encode().decode('latin-1', 'strict'))
pdf.cell(0,10, txt = '\n',ln=1 )
pdf.cell(0,10, txt = '*'*30,ln=1 )
except Exception as E:
print(str(E))
pdf.output('news_articles.pdf', 'F')
for i in range(len(image_list)):
os.remove(image_list[i])

Figure 3: First page of the generated pdf
We use FPDF extensively in our codebase with it’s advanced features such as support for custom fonts which is very essential if you want to work with many languages and you should definately check it out if you need a production ready PDF library in Python.